Аспекты
схемотехнического моделирования с
применением графических ускорителей
А.В.
Прикота,
вед. спец.,
A.C. Еремин,
инж.-прогр.,
А.В.
Морозов,
инж.- прогр.,
A.C. Перов,
инж.-прогр.,
prikota@spb.prosoft.ru,
ООО ЭРЕМЕКС, г.
Санкт-Петербург
Исследуются возможности
применения вычислений на GPU-ускорителях
для увеличения скорости моделирования электронных схем большой размерности.
Определяется эффективность применения параллельных вычислений при решении
линейных систем алгебраических уравнений.
The capabilities of computing on
GPU-accelerators to speed up simulation of electronic circuits with large dimension are considered. The efficiency of using parallel
computing for solving linear
systems of algebraic equations is
estimated.
Классическим
симулятором электронных схем является
программа SPICE
(Simulation Program with Integrated Circuit Emphasis), разработанная
в электронной исследовательской
лаборатории Калифорнийского Университета
Беркли и ставшая де-факто промышленным стандартом
при моделировании и верификации интегральных схем.
SPICE и SPICE-подобные программы обладают
максимальной точностью и достоверностью в схемотехническом моделировании. Это
обусловлено тем, что в них не используется никаких упрощений ни на этапе
составления моделей, ни на этапе решения системы уравнений цепи.
Стремительное развитие
микроэлектроники, переход на субмикронные уровни приводит к существенному
увеличению числа транзисторов в микросхемах и, как следствие, к росту
размерности моделируемых схем.
В то же самое время
вычислительная сложность алгоритмов SPICE моделирования
схем квадратично зависит от размерности моделируемой схемы. Эта зависимость
обусловливает колоссальные временные затраты, которые необходимы для
моделирования схем большой размерности, например, больших и сверхбольших
интегральных схем. Для моделирования таких
схем вынуждено применяются так называемые Fast-SPICE технологии. Они используют упрощения
в моделях элементов и применяют вычислительные алгоритмы, снижающие точность
расчетов. Это существенно повышает скорость моделирования, размерность схем,
но часто приводит к существенному
снижению достоверности моделирования, которая является определяющим фактором при разработке
и верификации интегральных схем.
Таким образом, насущной
задачей является увеличение скорости моделирования без потери точности.
Коллектив разработчиков
программы схемотехнического моделирования SimOne
компании “ЭРЕМЕКС” [7] на протяжении нескольких лет занимается вопросами
повышения скорости расчетов без потери точности SPICE-технологии. Немаловажное место в ряду
методов решения этой задачи занимают возможности применения GPU-ускорителей для задач моделирования.
Графические процессоры,
первоначально используемые только для ускорения трехмерной графики, со временем
стали мощными программируемыми устройствами, пригодными для решения задач, не
связанных с графикой.
Современные GPU – это
массивно-параллельные вычислительные устройства с очень высоким быстродействием
(свыше терафлопа) и большим объемом собственной памяти (DRAM).
За последнее время появилось большое число публикаций,
посвященных проблемам и особенностям применения GPU-ускорителей в SPICE моделировании. [1,2,3,4]. Работы в этом направлении сейчас активно
ведутся во многих мировых компаниях-лидерах на рынке коммерческих САПР. Так,
относительно недавно, в апреле 2008, американская компания Nascentric
представила первый в мире эмулятор SPICE OmegaSim GX,
в котором используется вычислительные мощности графических процессоров NVIDIA.
Решение OmegaSim GX основано на аппаратной платформе NVIDIA Tesla, которая имеет многопоточную архитектуру с массовым
параллелизмом. Платформа доступна в форме 128-ядерной платы расширения для шины
PCI Express, 256-ядерной настольной системы или
512-ядерной системы, рассчитанной на стоечный монтаж. При создании OmegaSim GX специалисты Nascentric
использовали инструментарий NVIDIA CUDA [5,6].
Математические аспекты
схемотехнического моделирования
В общем случае электронная
схема описывается нелинейной системой дифференциальных уравнений
![]() , (1)
, (1)
Здесь: ![]() – вектор переменных
состояния размерности
– вектор переменных
состояния размерности![]() ;
;
![]() – вектор зарядов
нелинейных емкостей
– вектор зарядов
нелинейных емкостей ![]() , потокосцеплений нелинейных индуктивностей
, потокосцеплений нелинейных индуктивностей ![]() ;
;
![]() – вектор токов
нелинейных резистивных элементов;
– вектор токов
нелинейных резистивных элементов;
![]() – матрица размером
– матрица размером ![]() линейных емкостей и индуктивностей;
линейных емкостей и индуктивностей;
![]() – матрица размером
– матрица размером ![]() линейных резистивных элементов и инциденций
токов элементов;
линейных резистивных элементов и инциденций
токов элементов;
![]() – вектор значений
независимых источников напряжения и тока.
– вектор значений
независимых источников напряжения и тока.
Вектор ![]() , как правило, содержит в себе нулевые компоненты. Системы
уравнений с таким вектором производных называют либо вырожденными системами,
либо системами дифференциально-алгебраических уравнений.
, как правило, содержит в себе нулевые компоненты. Системы
уравнений с таким вектором производных называют либо вырожденными системами,
либо системами дифференциально-алгебраических уравнений.
В зависимости от способа
формирования уравнений и применяемых математических моделей элементов в
качестве переменных ![]() могут выступать
узловые потенциалы, напряжения на элементах, токи, заряды и потокосцепления.
могут выступать
узловые потенциалы, напряжения на элементах, токи, заряды и потокосцепления.
Численное моделирование
электронных схем в SPICE разделяется на следующие основные виды:
1. Анализ по постоянному току (DC Analysis).
Поведение схемы в режиме
постоянного тока описывается следующей системой нелинейных алгебраических
уравнений
![]() , (2)
, (2)
где ![]() – фиксированные значения источников в момент времени t0.
Решение системы (2) производится методом Ньютона, требующим на каждой итерации
решения системы линейных алгебраических уравнений (СЛАУ):
– фиксированные значения источников в момент времени t0.
Решение системы (2) производится методом Ньютона, требующим на каждой итерации
решения системы линейных алгебраических уравнений (СЛАУ):
![]() ,
,
где ![]() – матрица малосигнальных параметров
нелинейных резистивных элементов схемы.
– матрица малосигнальных параметров
нелинейных резистивных элементов схемы.
Количество итераций (а, следовательно,
и число решений СЛАУ) определяется сложностью и размерностью моделируемой
схемы, и может доходить до сотен для решения одной нелинейной системы.
2. Частотный анализ (AC Analysis).
При проведении данного
вида анализа возникает необходимость в решении СЛАУ с комплексными числами
![]() , (3)
, (3)
![]() ,
, ![]() – вектор комплексных
амплитуд источников,
– вектор комплексных
амплитуд источников,
![]() – частота в заданном
диапазоне.
– частота в заданном
диапазоне.
Количество решений данной
СЛАУ при изменении параметра определяется пользователем и в среднем
составляет от тысяч до десятков тысяч.
3. Временной анализ (Transient
Analysis).
На каждом шаге численного
интегрирования системы (1) любой из методов (трапеций, Гира
и пр.) в итоге приводит к решению СЛАУ, в общем случае имеющей вид:
![]() , (4)
, (4)
в которой ![]() – параметр, зависящий от применяемого метода и от длины шага,
матрицы
– параметр, зависящий от применяемого метода и от длины шага,
матрицы ![]() и
и ![]() нелинейно зависят от
значений векторов
нелинейно зависят от
значений векторов ![]() , найденных на предыдущих шагах, а
, найденных на предыдущих шагах, а ![]() – правая часть системы
– также нелинейно зависит от найденных ранее величин. Количество шагов
интегрирования исходной системы (1), как правило, варьируется от тысячи до
миллиона и более. При этом на каждом шаге требуется решить несколько СЛАУ.
Таким образом, количество решений СЛАУ в течение временного анализа может
доходить до нескольких десятков миллионов.
– правая часть системы
– также нелинейно зависит от найденных ранее величин. Количество шагов
интегрирования исходной системы (1), как правило, варьируется от тысячи до
миллиона и более. При этом на каждом шаге требуется решить несколько СЛАУ.
Таким образом, количество решений СЛАУ в течение временного анализа может
доходить до нескольких десятков миллионов.
В SimOne
представлен дополнительный вид анализа схем:
4. Анализ устойчивости схемы (Stability Analysis).
Анализ устойчивости включает в себя
решение задачи определения собственных значений пучка матриц, а также поиска
корней полиномов, значения которых связаны с вычислением определителя пучка
матриц:
![]() , (5)
, (5)
где ![]() – комплексное число.
– комплексное число.
Нахождение определителя
по затратам и по реализации сравнимо с решением СЛАУ. Число нахождений детерминанта
определяется сложностью и размерностью моделируемой схемы и может достигать
десятков тысяч.
5. Анализ периодических режимов (PSS Analysis).
Для нахождения
периодических режимов схемы применяется
пристрелочный метод Ньютона (Shooting Newton),
который предполагает решение нескольких систем линейных алгебраических
уравнений с плотной матрицей чувствительностей с размерностью, равной
размерности матрицы системы. Применение LU-разложения даже для сравнительно
небольших схем становится нецелесообразным. Поэтому стараются применять
итерационные, методы.
Таким образом, очевидно,
что основное процессорное время при
моделировании электронных схем тратится на решение системы линейных уравнений и
оценку нелинейных параметров транзисторов. Применение GPU-ускорителей для
вычисления нелинейных параметров транзисторов не представляет особых
трудностей, поскольку параметры каждого
транзистора не зависят от других и могут считаться полностью параллельно.
Основной трудностью в
применении графических ускорителей для решения системы линейных уравнений
является слабая возможность распараллеливания процесса LU-факторизации матрицы системы. Это связано с сильной
разреженностью матрицы и ее характерной структурой. Для преодоления этих
трудностей предлагается такой способ формирования
уравнений электронной схемы, при
котором матрица системы будет иметь структуру определенного вида. К такой
матрице удобно применять принцип дополнения Шура, т.е. удобно работать блочными методами. В таком
случае процесс LU-факторизации
всей матрицы системы разбивается на N независимых друг от друга процессов факторизации блочных
подматриц. Каждое такое локальное разложение реализуется в SimOne с
помощью оригинальной программной технологии - кодового матричного процессора – набора определенных команд,
учитывающих структуру матрицы, изменяемость/неизменяемость элементов
подматриц.
Согласно проведенным
исследованиям [1], перенос расчетов
транзисторных нелинейностей на графические ускорители позволит достигнуть
четырехкратного увеличения скорости
моделирования, а реализация решения СЛАУ
на них может ускорить расчеты на порядок и выше [2,3].
Решение СЛАУ большой
размерности
Для решения СЛАУ и вычисления
определителя используется LU-разложение
исходной матрицы ![]() :
: ![]() (6)
(6)
 – нижне-треугольная матрица,
– нижне-треугольная матрица,
 – верхне-треугольная матрица.
– верхне-треугольная матрица.
В этом случае система линейных
уравнений вида ![]() решается следующим
образом:
решается следующим
образом:
![]()
Решается система с нижне-треугольной
матрицей:
![]() ,
, ![]() - вспомогательный вектор,
- вспомогательный вектор,
после
чего – с верхнее-треугольной: ![]() .
.
Определитель матрицы ![]() равен произведению диагональных
элементов матрицы
равен произведению диагональных
элементов матрицы ![]() :
:
![]() .
.
Для того чтобы LU-разложение (6) было численно
устойчиво, необходимо производить выбор ведущего элемента; обычно выбирают
максимальный в строке или столбце.
Для больших матриц целесообразно
использовать декомпозиционные методы решения.
Наиболее эффективным методом является приведение матрицы к блочно-окаймленному
виду, при котором система запишется как
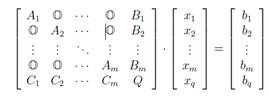 (7)
(7)
Здесь ![]() – нулевой блок подходящей размерности.
– нулевой блок подходящей размерности.
Диагональные блоки ![]() - квадратные с
размерностями
- квадратные с
размерностями ![]() ,
, ![]() .
.
Блок ![]() имеет размерность
имеет размерность ![]() . Блоки
. Блоки ![]() и
и ![]() имеют соответственно размерности
имеют соответственно размерности ![]() и
и ![]() .
.
Решение системы
производится по формулам:
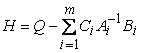 (8)
(8)
![]() (9)
(9)
![]() (10)
(10)
![]() ,
,![]() (11)
(11)
Определитель матрицы А находится по формуле
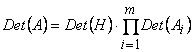 (12)
(12)
Таким образом, для
получения искомого вектора x или для нахождения
определителя требуется число действий, пропорциональное ![]() ,
что существенно ниже, чем
,
что существенно ниже, чем ![]() , и часто меньше
, и часто меньше ![]() .
.
Существует два основных
подхода, позволяющих получить СЛАУ в виде (7). Первый связан с преобразованием
матрицы A с использованием теории графов, например, алгоритм вложенных сечений.
Второй – с формированием исходных уравнений системы (1) в блочном виде. Это
достигается за счет функционального разделения исходной электрической
схемы (см. рис.
1).
Обращение блоков ![]() нахождение матричных
произведений
нахождение матричных
произведений ![]() , произведений матриц на векторы
, произведений матриц на векторы ![]() ,
, ![]() в формулах (8)–(11)
являются независимыми операциями и прекрасно поддаются распараллеливанию.
в формулах (8)–(11)
являются независимыми операциями и прекрасно поддаются распараллеливанию.
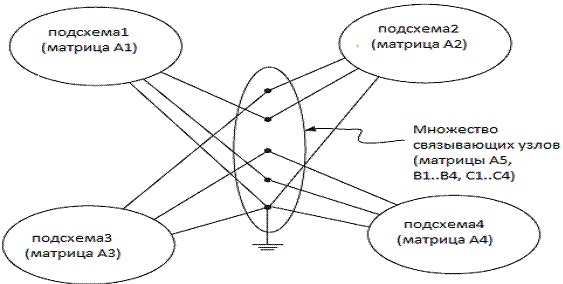
рис. 1 Пример функционального
разделения электрической схемы
Технология применения
GPU для решения СЛАУ
GPU содержит ряд
независимых друг от друга потоковых
мультипроцессоров (SM - Streaming Multiprocessor), каждый из которых способен одновременно
выполнять 768 (1024 - для более поздних моделей) нитей. Нить - наименьшая
единица обработки, исполнение которой может быть назначено операционной системой. Нити разбиваются
на группы по 32 нити, называемые warp'ами. Только
нити в пределах одного warp'а
выполняются физически одновременно. При этом управление warp'ами
осуществляет сам GPU. За счет столь высокого параллелизма GPU способны
обрабатывать большие объемы данных, обходя по быстродействию CPU.
Однако это преимущество
налагает свои ограничения: параллельная обработка данных идет по единой
инструкции, а частые обращения к памяти GPU могут сильно замедлить работу,
поэтому их следует сводить к минимуму. Кроме того, возникает необходимость
задания инструкций обработки данных. Это можно осуществить с
помощью API (OpenGL или Direct3D), налагающего
ограничения, логичные для графики, но излишние для иных задач. Другая
возможность - использовать специально созданные средства, ориентированные на
решение сложных задач CUDA, OpenCL .
CUDA [8] –
программно-аппаратная архитектура, разрабатываемая компанией NVidia, в настоящее время является наиболее
стабильным и легким в освоении продуктом с лучшим, чем у конкурентов
функционалом. Существенным преимуществом являются также разнообразные и
развитые средства разработки, отладки и профилирования кода.
OpenCL
[9] разрабатывается и поддерживается некоммерческим консорциумом Khronos Group, в который входят много крупных
компаний, включая Apple,
AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment и др. Технология OpenCL
привлекательна, прежде всего, своей переносимостью. В настоящее время она
работает на GPU фирм NVidia
и AMD, на процессорах с архитектурой x86 (AMD APP) и IBM Power
[10]. Свой вариант реализации готовит фирма Intel
[11].
Доступная на текущий
момент информация о сравнении производительности этих двух технологий
достаточно неоднозначна. В работе [12] отмечается, что производительность ядра OpenCL проигрывает CUDA от 13% до 63%. С другой стороны, по
результатам исследований [13] OpenCL значительно
медленнее CUDA на небольших задачах, но сравним, а иногда и быстрее, при
больших объемах вычислений. Следует отметить, что обе технологии продолжают
активно развиваться.
Концепция построения
CUDA: GPU (устройство, device) выступает в роли
массивно-параллельного сопроцессора к CPU (host).
Программа на CUDA задействует как CPU, так и GPU. При этом обычный
(непараллельный) код выполняется на CPU, а для массивно-параллельных вычислений
соответствующий код выполняется на GPU как набор одновременно выполняющихся
нитей (threads).
Общий алгоритм программы
с использованием CUDA:
·
выделение
памяти на GPU;
·
копирование
данных из памяти CPU в выделенную память GPU;
·
запуск
ядра – функции, выполняемой на большом количестве нитей GPU;
·
копирование
результата в память CPU и освобождение выделенной памяти GPU.
Практические результаты
Рассмотрим применение GPU-ускорителей для решения задачи
решения СЛАУ с плотной матрицей, возникающей при поиске периодических режимов
схем.
В качестве метода
решения СЛАУ выберем итерационный метод обобщенных минимальных невязок Gmres
с итерациями Арнольди [14].
Наиболее трудоемкой частью метода GMRES является операция умножения матрицы на
вектор, которую необходимо проводить на каждой итерации. Его перенос на GPU позволит значительно повысить
скорость получения решения. Исходная
матрица не меняется, это позволяет снизить затраты на обмен данными и, один раз
загрузив в память GPU,
использовать ее на всех итерациях.
Матрица и вектор
загружаются в глобальную память GPU. Однако, вместо того, чтобы многократно извлекать во
время умножения значения из медленной глобальной памяти, удобнее один раз их
прочесть в разделяемую память и дальше брать ее оттуда. Разделяемая память
размещена в самом мультипроцессоре и доступна на чтение и запись всем нитям
блока. При этом перенос данных из глобальной в разделяемую память
осуществляется параллельно: каждой нити для копирования назначаются свои
участки памяти. Элементы матрицы назначаются нити в соответствии с ее
положением в блоке нитей и положению блока в сетке.
Параллельно запускается
множество блоков 16х16 нитей. Нити каждого блока выполняются одновременно и
умножают 16 строк матрицы на вектор.
Тестирование проводилось
на компьютере с процессором AMD
Athlon(tm) 64 Processor 3800++ 2.41GHz, оперативной памятью 1,00 GB, видеоадаптером NVIDIA GeForce 9500 GT.
По результатам тестов
(табл. 1) проведено сравнение времени, затрачиваемого при умножении на GPU и CPU. Тесты показали, что:
·
использование
параллельных вычислений на GPU
позволяет в разы увеличить скорость.
·
самым
затратным является запись данных в глобальную память GPU.
Таблица
1.
Результаты тестирования
|
Размер
матрицы А |
50х50 |
500х500 |
103х103 |
5000х5000 |
104x104 |
|
Время
загрузки данных в глобальную память GPU (мс) |
0,3433 |
1,3527 |
3,2627 |
71,326 |
309,4380 |
|
Время
вычисления на GPU (мс) |
0,0432 |
0,5809 |
1,7919 |
43,6351 |
173,8403 |
|
Время
чтения результата (мс) |
0,0022 |
0,0209 |
0,0237 |
0,0389 |
0,0608 |
|
Суммарное
время |
0,3887 |
1,8545 |
5,0783 |
115 |
483,3391 |
|
Время
вычисления на CPU
(мс) |
0,0029 |
4,4409 |
15,7918 |
527,6771 |
2659,8752 |
Литература
1. Kanupriya Gulati и др.
Fast circuit simulation on graphics processing units // Proceedings of the 2009
Asia and South Pacific Design Automation Conference IEEE Press Piscataway, NJ,
USA. 2009. - P. 403–408.
2. Kapre, N., DeHon,
A. Parallelizing sparse Matrix Solve for SPICE circuit simulation using FPGAs
// IEEE International Conference on Field-Programmable Technology. FPT 2009.
9-11 Dec. 2009. - P. 190–198.
3. Jeremy
Johnson и др.
Sparse LU Decomposition using FPGA // 9th International Workshop on
State-of-the-Art in Scientific and Parallel Computing May 13-16ю -
NTNU, Trondheim, Norway.
4. Rick
Poore. GPU-Accelerated Time-Domain Circuit Simulation
// IEEE Custom Integrated Circuits Conference (CICC) paper 20-3, 2008.
5. http://www.ixbt.com/news/all/index.shtml?10/33/61
6. http://www.allabouteda.com/nascentric-announces-omegasim/
7. http://www.eda.eremex.ru/products/simone/
8. Что такое CUDA? // Доступно по адресу http://www.nvidia.ru/ object/what_is_cuda_new_ru.html
на
22.04.2011.
9. OpenCL – The open standard for parallel
programming of heterogeneous systems // Доступно по адресу http://www.khronos.org/opencl/ на 22.04.2011
10. IBM
releases OpenCL Development Kit for Linux on Power
v0.3 – OpenCL 1.1 conformant release available // Доступно по адресу
https://www.ibm.com/developerworks/mydeveloperworks/blogs/
80367538-d04a-47cb-9463-428643140bf1/entry/ibm_releases_opencl_development_kit_for_linux_on_power_v0_3_opencl_1_1_
conformant_release_available6?lang=en на
22.04.2011
11. Intel OpenCL SDK // Доступно по адресу http://software.intel.com/en-us/articles/intel-opencl-sdk/ на 22.04.2011
12. Karimi K., Dickson N. G., Hamze F. A Performance Comparison of CUDA and OpenCL / Preprint at ArXiv // Доступно по адресу
http://arxiv.org/ftp/arxiv/papers/1005/1005.2581.pdf на 22.04.2011
13. NVIDIA
Fermi with CUDA and OpenCL // Доступно по адресу
http://blog.accelereyes.com/blog/2010/05/10/ nvidia-fermi-cuda-and-opencl/ на
22.04.2011
14. Баландин М.Ю., Шурина Э.П. Методы решения СЛАУ
большой размерности. - Новосибирск, Изд-во НГТУ, 2000. - 70 c.