Классификация сложных систем
(биологических объектов) по небольшому числу измеряемых параметров
В. А. Никулин,
инж., vnik68@mail.ru,
ИПЭЭ РАН, ИПУ РАН, г. Москва
Аннотация
Мы
уже публиковали доклад о «пространствах, метризованных плотностью вероятности»,
и о требованиях к формальной коллекции, которые позволяют поставить задачу
классификации в псевдо-статистическом виде. Здесь (используя эти пространства
при неполном выполнении этих требований) удаётся решить задачу о выявлении цветовых
форм рыжей полёвки — Clethrionomys
или Myodes glareolus, на примере
которой демонстрируются характерные особенности предлагаемого метода. Также
решается задача о выделении некоторых видов и родов птиц по промерам маховых
перьев 2–5 пальцев, что может быть полезно для анализа останков птиц в
авиационной орнитологии.
Abstract
We
already published the report about “spaces with metrics of density of
probability” and about requirements to formal collection which allow to set the
task of classification in a pseudo-statistical kind. Here (with using these
spaces at incomplete performance of these requirements) were solved two tasks:
about revealing the color forms of bank vole — Clethrionomys or Myodes
glareolus, to demonstrate typical particularities of the proposed method,
and about separation of some species and some genuses of the birds through
measurements of remiges of 2–5 fingers, it may be useful to analysis of remains
of birds in aviation ornithology.
Введение
Задачу
классификации или распознавания сложных систем нередко приходится решать при
малом числе доступных параметров. Однако параметры в таких системах обычно взаимосвязаны,
что всё же позволяет решить задачу.
Ранее
мы уже представляли доклад [1] о свойствах «пространств,
метризованных плотностью вероятности», и требованиях к формальной коллекции, при которых задача классификации ставится,
как псевдо-статистическая.
Здесь
мы рассмотрим характерные особенности нашего метода классификации на наглядном примере
выделения цветовых форм рыжей полёвки — Clethrionomys
или Myodes glareolus, после чего испытаем метод
на задаче распознавания уже известных биологических видов и родов птиц.
Математическое определение «пространств, метризованных
плотностью вероятности»,
и построение их статистического аналога[1]
Рассмотрим
параметр, на множестве значений которого заданы порядок и вероятностная мера.
Тогда, по определению, существует и распределение вероятности
![]() (1)
(1)
![]() — значение распределения
вероятности и
— значение распределения
вероятности и ![]() — вероятность того,
что при однократном испытании будет реализовано любое значение
— вероятность того,
что при однократном испытании будет реализовано любое значение ![]() , не превосходящее
, не превосходящее ![]() по заданному порядку. То
есть, распределение вероятности немедленно отображает ранговую «ось» значений
параметра на единичный отрезок вероятностей.
по заданному порядку. То
есть, распределение вероятности немедленно отображает ранговую «ось» значений
параметра на единичный отрезок вероятностей.
При
неизменном распределении вероятности задать метрику, вообще говоря, можно
многими способами. Один такой способ — особый, поскольку не требует
дополнительной аксиоматики. Достаточно положить
![]() (2)
(2)
![]() и
и ![]() — значения параметра
(для определённости,
— значения параметра
(для определённости, ![]() ),
), ![]() — вероятностное
«расстояние» между этими значениями, а
— вероятностное
«расстояние» между этими значениями, а ![]() и
и ![]() — соответствующие
значения распределения вероятности. При
— соответствующие
значения распределения вероятности. При ![]() и
и ![]() имеем
имеем
![]() (3)
(3)
![]() — значение параметра,
преобразованное к вероятностным единицам, а
— значение параметра,
преобразованное к вероятностным единицам, а ![]() — значение распределения
вероятности для исходного значения
— значение распределения
вероятности для исходного значения ![]() . Поскольку выражение
. Поскольку выражение ![]() в формуле (2)
есть средняя плотность вероятности на открытом слева отрезке
в формуле (2)
есть средняя плотность вероятности на открытом слева отрезке ![]() , будем говорить, что «ось» параметра метризованна плотностью
вероятности. Поскольку при такой метрике плотность вероятности всегда равномерна
и равна 1 на закрытом отрезке
, будем говорить, что «ось» параметра метризованна плотностью
вероятности. Поскольку при такой метрике плотность вероятности всегда равномерна
и равна 1 на закрытом отрезке ![]() , параметр, значения которого преобразованы по
формуле (3), будет равномерно плотной случайной величиной.
, параметр, значения которого преобразованы по
формуле (3), будет равномерно плотной случайной величиной.
Рассмотрим
теперь случай нескольких стохастических параметров, значения которых отображены
на соответствующие единичные отрезки по формуле (3). Единичный куб, оси
которого соответствуют этим отрезкам, будем называть пространством равномерно плотных случайных величин. Старое название
— «пространство, метризованное
плотностью вероятности», не вполне корректно[2], так как многомерная плотность
вероятности будет обладать нетривиальным и весьма полезным свойством, которое
сформулировано в следующей Теореме А. В. Коганова[3].
Теорема 1. Многомерная
плотность вероятности будет равномерна во всём объёме единичного куба, если
осями этого куба являются случайные величины, метризованные плотностью вероятности,
и если все эти величины статистически независимы.
Верно и обратное: если случайные величины, метризованные
плотностью вероятности, являются осями единичного куба, плотность вероятности
внутри которого равномерна, они независимы.
Теорема 1
формулирует главное свойство «пространств, метризованных плотностью
вероятности», которое в перспективе позволяет использовать их для
фундаментального описания и анализа случайных величин. Однако на практике реализован
только эмпирический подход, который на основании статистической выборки
позволяет делать выводы о вероятностной зависимости (или независимости)
измеренных параметров — столбцов матрицы данных, строки которой ведут себя
стохастически. Для наведения такой статистики потребовалось сконструировать
статистический аналог «пространств, метризованных плотностью вероятности», —
«пространства, метризованные выборочной частотой»[4].
По аналогии понятно, что основой определения таких пространств должно стать
распределение выборочной частоты, поэтому, прежде всего, мы напишем частотный
аналог формул (1) и (3):
![]() (4)
(4)
![]() — выборочная частота
всех измеренных значений параметра, не превосходящих одно из таких значений —
— выборочная частота
всех измеренных значений параметра, не превосходящих одно из таких значений — ![]() ,
, ![]() — порядковый номер
значения
— порядковый номер
значения ![]() среди других зарегистрированных
значений параметра (при нумерации от меньших к большим, начиная с 1),
среди других зарегистрированных
значений параметра (при нумерации от меньших к большим, начиная с 1), ![]() — число
зарегистрированных значений параметра
— число
зарегистрированных значений параметра ![]() ‑ой по порядку величины,
‑ой по порядку величины, ![]() — число
зарегистрированных значений параметра величины
— число
зарегистрированных значений параметра величины ![]() ,
, ![]() — объём выборки, а
— объём выборки, а ![]() — координата исходного
значения
— координата исходного
значения ![]() на преобразованной
(отображённой на единичный отрезок) «оси» параметра. Отметим особо: хотя все
на преобразованной
(отображённой на единичный отрезок) «оси» параметра. Отметим особо: хотя все ![]() суть рациональные
величины — значения
суть рациональные
величины — значения ![]() , при заданной выборке им соответствуют конкретные порядковые
номера, что приближает преобразованные по формуле 4 координаты к ранговым.
, при заданной выборке им соответствуют конкретные порядковые
номера, что приближает преобразованные по формуле 4 координаты к ранговым.
Из
формулы (4) немедленно следует более простое соотношение
![]() (5)
(5)
которое вычисляет выборочное частотное «расстояние»
между двумя соседними по величине наблюдавшимися значениями параметра.
Формула (5) удобна для поточной обработки последовательно поступающих
элементов выборки. Например, если вновь поступивший элемент имеет ![]() ‑е по порядку значение параметра, аддитивные поправки (разной
величины) получат только ранговые координаты, начиная с
‑е по порядку значение параметра, аддитивные поправки (разной
величины) получат только ранговые координаты, начиная с ![]() ‑й, и большие. Таким образом, метризованные выборочной
частотой единичные отрезки при добавлении новых элементов выборки способны
растягиваться на одних участках и, соответственно, сжиматься на других (за счёт
перенормирования на больший объём выборки).
‑й, и большие. Таким образом, метризованные выборочной
частотой единичные отрезки при добавлении новых элементов выборки способны
растягиваться на одних участках и, соответственно, сжиматься на других (за счёт
перенормирования на больший объём выборки).
Отметим
ещё одну особенность преобразования, заданного формулами (4) и (5): все
«точечные» частотные координаты ![]() имеют нулевую
«частотную массу», подобно тому, как нулевую «вероятностную массу» имеют «точечные»
значения непрерывной случайной величины. То есть, по формулам (4) и (5) мы даже
дискретное множество допустимых значений параметра отображаем на непрерывный
единичный отрезок, тогда как обычно, наоборот, от непрерывного множества переходят
к его дискретному покрытию.
имеют нулевую
«частотную массу», подобно тому, как нулевую «вероятностную массу» имеют «точечные»
значения непрерывной случайной величины. То есть, по формулам (4) и (5) мы даже
дискретное множество допустимых значений параметра отображаем на непрерывный
единичный отрезок, тогда как обычно, наоборот, от непрерывного множества переходят
к его дискретному покрытию.
Теперь
мы достаточно «вооружены», чтобы рассмотреть первый пример.
Выделение цветовых форм рыжей полёвки по
промерам белизны и оттенка шкурки[5]
Окраска
129‑и рыжих полёвок, пойманных в 6‑и разных местах Тверской
области, определялась с помощью нового методического подхода [2]: была создана компьютерная программа для
колориметрической оценки светорассеивающих образцов. Определялись стандартные
цветовые показатели белизны и оттенка.
Используя
эти данные, мы попытались выделить в «плоском пространстве» цветовые формы,
разделённые хиатусом либо имеющие «хороший» — удобный в использовании диагноз.
Для этого, прежде всего, измеренные значения обоих параметров были
преобразованы по формуле (4). Затем в полученном «пространстве,
метризованном выборочной частотой», был проведён кластерный анализ с эвклидовой
метрикой[6]:
строились так называемые кластеры (иногда говорят — «классы») типа слабого сгущения
[3, с. 46], в которых элемент принадлежит
кластеру тогда и только тогда, когда существует другой элемент, принадлежащий
тому же кластеру и удалённый от первого не более, чем на заранее выбранное расстояние
![]() , которое мы называем радиусом цельности кластеров.
, которое мы называем радиусом цельности кластеров.
Полученные
результаты представлены на рис. 1, где хорошо видны три цветовые формы.
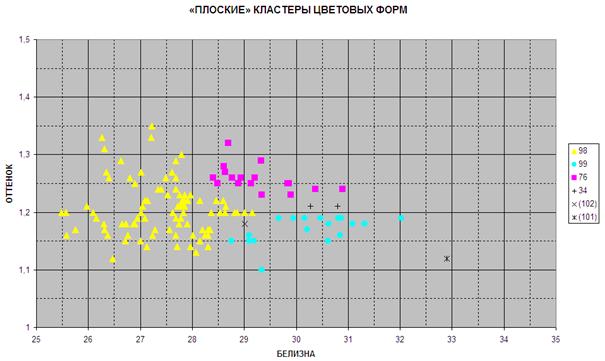
рис. 1 Кластеры цветовых
форм рыжей полёвки, построенные по промерам белизны и оттенка в «пространстве,
метризованном выборочной частотой», представлены разными маркёрами и
соответствующими номерами в легенде. Для демонстрации особенностей метода обе
оси изображены в масштабе исходных — не преобразованных значений соответствующих
параметров
Действительно, кластер 98 — это зверьки со
шкурками малой белизны, при большом, в целом, разбросе значений оттенка. Однако
среди них всё же преобладают шкурки среднего оттенка, благодаря чему светлые
шкурки примерно в равных частях хорошо разделяются на две формы — слабого и
сильного оттенка (кластеры 99 и 76, соответственно). Оставшиеся три кластера, —
34 (две шкурки), 102 и 101 (по одной шкурке в каждом), — слишком малы, чтобы
делать какие-то выводы, но в кластерах 34 и 101 всё же можно заподозрить два
«осколка» реально существующей редкой формы — очень светлых зверьков преимущественно
среднего оттенка, «недостающие» экземпляры которых, возможно, должны занять
место «противоположное» кластеру 98 на «светлой стороне» оси белизны.
Возникают
вопросы: насколько можно доверять полученным результатам, и вообще, как нам
удалось решить нестатистическую по сути задачу классификации чисто статистическим
методом? Нам известны только два способа проверить правильность решения задачи
о цветовых формах рыжей полёвки: первый — собрать более полную коллекцию,
второй — теоретически обосновать существование именно таких форм. Оба эти
способа далеко выходят за пределы настоящего доклада.
Псевдо-статистическое решение задачи
классификации и требования к формальной коллекции
Рассмотрим
классический мысленный эксперимент с «чёрным ящиком», куда помещены все
собранные нами шкурки[7].
Очевидно, что при идеальной постановке такого эксперимента выборочные частоты
«доставания» экземпляров разных цветовых форм будут попросту равны доле этих
форм среди всех шкурок, «положенных в ящик». Поскольку нас интересуют диагнозы
форм, а не их обычность (или редкость) в природе, все формы в идеале должны
быть представлены примерно равным числом экземпляров[8].
Например, кластеры 34 и 101 на рис. 1 вполне могут представлять редкую
цветовую форму, но проверить это мы не можем, так как, если эта форма
существует, её кластер «разорван» кластерами более обычных форм (в нашем случае
— кластером 99).
«Содержимое
чёрного ящика» при псевдо-статистической постановке задачи классификации мы
будем называть формальной коллекцией.
Наиболее общие требования к ней состоят в том, что более типичные для
изучаемого разнообразия сочетания признаков, как бы редки не были соответствующие
формы, должны быть представлены бо′льшим числом экземпляров выборки[9]
(подробнее смотри [1]). Образно говоря, каждая форма представлена «облаком»
экземпляров, более или менее кучно рассеянных вокруг наиболее типических (если
угодно, — архетипических) областей пространства параметров. Для таких областей
формулируют параметрические описания — диагнозы.
Получается
порочный круг — для правильного выявления форм надо заранее знать, какие формы
существуют, чтобы равно представить их в коллекции. Однако обычно мы априори
немало знаем об изучаемом разнообразии форм, и эти знания требуется только
дополнить и (или) уточнить.
Распознавание некоторых биологических видов и
родов птиц
по промерам первостепенных маховых перьев 2–5 пальцев[10]
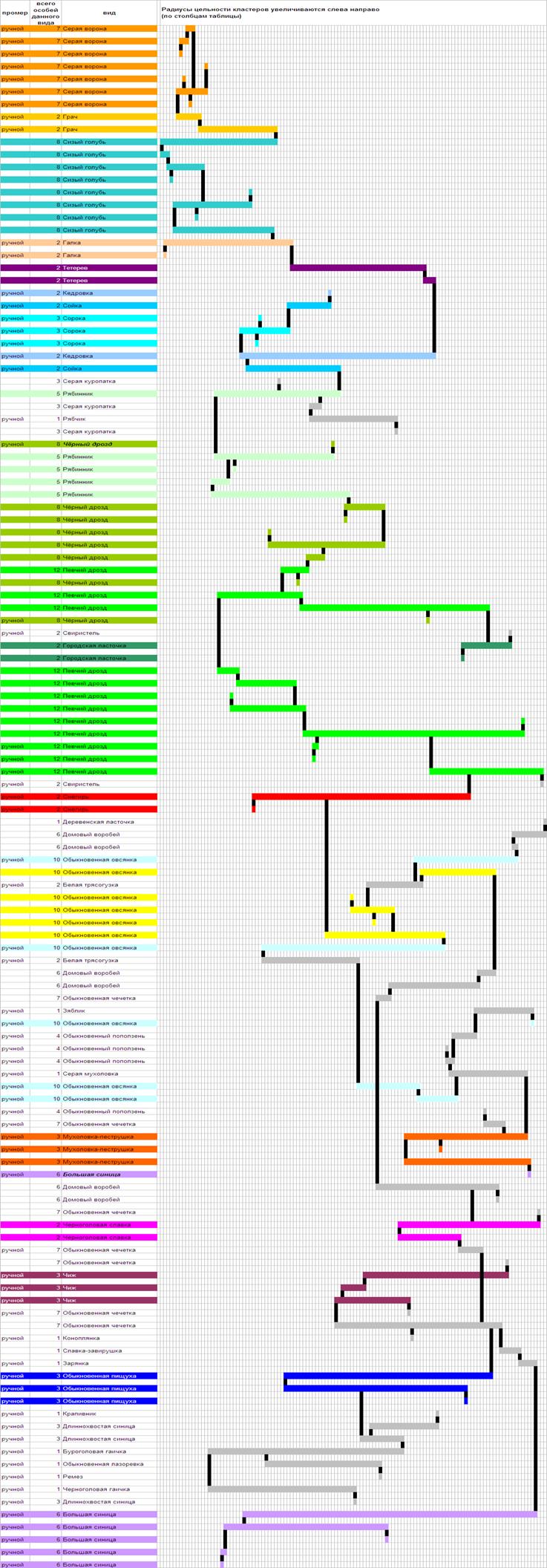
рис. 2 Граф
последовательности соединения строк — экземпляров формальной коллекции в
кластеры, радиус цельности которых увеличивается слева направо по столбцам.
В шапке строк слева от названия вида указано общее число особей данного
вида в коллекции. Экземпляры, отмеченные звёздочкой в первом столбце, были
промерены «вручную» средствами Corel Draw
(остальные экземпляры промерялись при помощи специально разработанной программы
PteroMetr1). Курсивом выделены видовые названия тех экземпляров, которые по
значениям отдельных параметров существенно уклоняются от остальных коллекционных
экземпляров своего вида.
После
столкновения птиц с воздушными судами нередко остаются только фрагменты их тел,
для которых невозможно поставить систематический диагноз по обычно используемым
признакам. В работах [4 и 5] авторы показывают, что математическими методами
распознавания образов можно неплохо распознать вид род и семейство птицы по промерам
первостепенных маховых перьев 2–5 пальцев.
Всего
было промерено 123 особи по 4 пера у каждой и по 12 промеров на каждое перо (то
есть, каждая особь была промерена по 48 параметрам). При обработке обсуждаемым
методом некоторые параметры в последствии были исключены, как предположительно
ненадёжные, что повысило качество распознавания. В итоге, каждая особь анализировалась
нами по 24 параметрам (по 6 промеров на каждое из 4‑х перьев).
Как
и в предыдущей задаче, значения каждого параметра были преобразованы по
формуле (4), в полученном «пространстве, метризованном выборочной
частотой», был проведён кластерный анализ с эвклидовой метрикой, и построены
кластеры типа слабого сгущения [3, с. 46].
Результаты
представлены на рис. 2, где хорошо видны обособившиеся формы.
Действительно, разрезанием графа легко можно выделить связные подмножества
вершин, соответствующие серой вороне (Corvus cornix), сизому голубю (Columba livia), сороке (Pica pica),
дрозду‑рябиннику (Turdus pilaris), певчему дрозду (Turdus philomelos),
а так же в целом всем коллекционным дроздам — перечисленные виды вместе с
чёрным (Turdus merula),
и низшим врановым — сорока вместе с сойкой (Garrulus glandarius) и кедровкой (Nucifraga caryocatactes).
Почти полностью (5 особей из 6‑и) отделяются большие синицы (Parus major),
у которых, впрочем, «вылетевшая» особь сильно отличается по значениям отдельных
параметров. Отделились и многие виды, представленные малым числом особей,
которое требуется увеличить для оценки качества распознавания: грач (Corvus frugilegus) —
2 особи, галка (Corvus monedula) — 2, тетерев (Tetrao tetrix) —
2, городская ласточка (Delichon urbica) — 2, снегирь (Pyrrhula pyrrhula) —
2, мухоловка‑пеструшка (Ficedula semitorquata) — 3, черноголовая славка (Sylvia atricapilla) —
2, чиж (Carduelis spinus) —
3 и обыкновенная пищуха (Certhia familiaris) — 3. Ещё 12 видов
представлены единичными особями, а качество распознавания остальных 9‑и
видов коллекции оказалось неудовлетворительным.
Любопытно,
что использованный в работах [4 и 5] метод распознавания[11]
эффективен только при некоррелированных параметрах, в то время как наш метод,
напротив, основан на их статистической связности, частным случаем которой
является корреляция. Эффективность обоих методов можно рассматривать как
дополнительное свидетельство их объективности и полноты (в том смысле, что
при распознавании биологических видов и родов возможности данной формальной
коллекции, по-видимому, были исчерпаны).
Есть,
однако, и различия полученных результатов. Так, в работе [5] методом
НИЦ РО удалось разделить все виды роды и семейства коллекции. Однако при
этом для каждой группы пришлось специально подбирать параметры алгоритма
распознавания. Наш метод сработал автоматически, хотя некоторые виды и почти
все более крупные таксоны не были распознаны.
В обоих
случаях, по сути, получилась классификация птиц по особенностям строения
вершины крыла.
Заключение
Приведённые
примеры просты и показательны, но не являются ни исключительно удачными, ни
наиболее дотошными вариантами испытания метода, который в силу своей
«автоматичности» оказался исключительно удобен для оперативного анализа
«многомерных» данных.
Литература
3.
Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика,
1988.
4.
Силаева О. Л.,
Вараксин А. Н., Ильичёв В. Д. Таксономическая идентификация
по перу с помощью кластерного анализа // Актуальные проблемы экологии и
природопользования. Вып. 12: Сборник научных трудов. — М.: Луч, 2010. —
С. 191–196.
5.
Силаева О. Л.,
Вараксин А. Н., Ильичёв В. Д. Экспертиза перьевого
материала с использованием методов анализа многомерных данных // Вестник РУДН.
— (В печати).