Проблемы оптимизации быстродействующих систем
на кристалле с
проектно-технологическими нормами 180 нм
В.И. Мамычев,
инж. ОАО
«НЗПП с ОКБ», mamychev@nzpp,
В.И. Сединин,
д.т.н, проф., sedvi@bk.ru,
СибГУТИ, г. Новосибирск
В статье рассматривается
методика и алгоритмы оптимизации для систем в которых
быстродействие имеет критичное значение. Рассматриваемая работа ориентирована
на микроэлектронную фабрику TSMС. Приведен
сравнительный анализ основных подходов в повышении качества оптимизации.
Ключевым фактором определяющим сложность реализации
сверх больших интегральных схем(СБИС) являются
требования предъявляемые к ее характеристикам. Другими словами – величины
параметров представленных в техническом задании на проект.
В силу требования предъявляемых современным
быстродействующим специализированным схемам, предложим следующие критерии
оптимизации в порядке убывания приоритетов: реализация параметров,
быстродействие, потребление, площадь, стоимость.
Разработчики СБИС, как правило, пытаются решить
проблемы быстродействия на начальной стадии маршрута проектирования. Это
делается за счет выбора или разработки архитектуры. При насыщении архитектурных
процессов оптимизации начинается процесс технологической оптимизации и оптимизации САПР.
В качестве примера в данной работе используются
данные крупнейшей в мире микроэлектронной фабрики TSMC.
Рассмотрим технологические ограничения при
разработке СБИС. С точки зрения быстродействия любую синхронную цифровую схему
можно представить в виде набора логических путей как на рисунке 1.
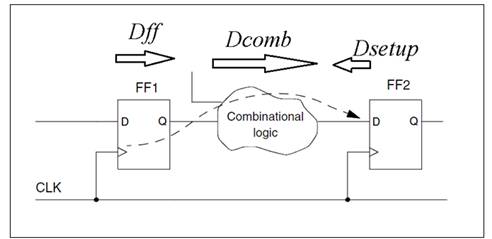
Рис. 1. Общий вид логического пути
Использование стандартных библиотек фабрики TSMC
дает результаты представленные в таблице 1. Для
анализа использовалась 180нм – библиотека для трех граничных случаев условий
работы схемы(далее «корнер»). В качестве звена комбинаторной
логики был выбран обычный инвертор. Синтез схемы проводился в среде Design Compiler (SYNOPSYS).
Таблица 1
|
Корнер библиотеки |
Описание корнера |
Максимальная частота работы |
Потребление |
Площадь |
|
|
T, C |
V |
||||
|
Typical |
25 |
VDD |
2,85 ГГц |
925
мкВт |
105.4 мкм2 |
|
Best |
-40 |
VDD+10% |
4,00 ГГц |
1600 мкВт |
105.4 мкм2 |
|
Worst |
125 |
VDD-10% |
1,80 ГГц |
470
мкВт |
105.4 мкм2 |
T – предполагаемая температура микросхемы,
V – напряжение питания ядра микросхемы(VDD –
номинальное напряжение равное 1,8В для данной
технологии).
Данные результаты пригодятся нам для оценки использования
ресурсов при переходе на другой корнер.
Как видно из представленных результатов, внешние
условия работы схемы оказывают на ее быстродействие значительное влияние. Как
будет показано далее реализация схем на библиотеках «Worst»
требует почти в два раза большей площади и потребления кристалла по отношению к
«Typical».
Рассмотрим схему на рисунке 1 более подробно. Время
отводимое комбинаторной логике(КЛ) определяется
следующим соотношением:
![]() , (1)
, (1)
где
Tc – максимальное время которое может быть использовано КЛ
Tlatch – время прибытия тактового
сигнала на триггер-приемник
Tsource – время прибытия тактового
сигнала на триггер-источник
Tdff – время задержки сигнала
на триггере-источнике
Tsff – время предустановки для сигнала для триггера-приемника.
Если пренебречь временным разбалансом
в прибытии тактового сигнала к данным триггерам, то можно записать:
![]() , (2)
, (2)
где
Tclk – время одного периода тактовой частоты.
Как следует из библиотеки tsmc
для двухступенчатого триггера с сигналом сброса для различных корнеров:
Tdff = 300пс – 500пс;
Tsff = 30пс – 120пс;
Таким образом максимальное
время доступное КЛ составляет около 770пс – 380пс для частоты тактового сигнала
1ГГц.
Время задержки на двухвходовом вентиле (ИЛИ-НЕ, И-НЕ) составляет около 50пс – 80пс.
Из вышесказанного следует, что логическая функция заключенная в КЛ может иметь от 15 до 5 вентилей.
Однако, наличие входных емкостей и различных паразитных
эффектов приводит к уменьшению данного ресурса.
Существует два основных способа повышения
быстродействия СБИС при отсутствии возможности архитектурной оптимизации. Это
конвейеризация и мультиплексирование.
Конвейеризация предполагает наличие дополнительных
цифровых путей с запасом времени для КЛ в которые
можно перенести часть КЛ из другого цифрового пути без изменения общей функции
схемы.
На рисунке 2 приведен пример. Как видно из схемы,
первый цифровой путь имеет задержку КЛ равную 23нс; второй путь не имеет КЛ,
т.е. задержка равна нулю; третий путь имеет задержку 4нс. Если для примера
предположить, что максимальное время для КЛ должно быть не более 12нс, то мы
увидим, что первый путь имеет дефицит времени. Напротив, второй путь имеет
запас.
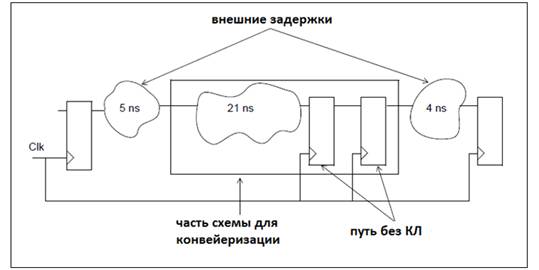
Рис. 2. Пример схемы до
конвейеризации
На рисунке 3 предложен вариант с конвейеризацией.
Теперь схема не имеет цифровых путей с временем
задержки более 12нс. При этом произошла балансировка задержки равной 21нс на
два пути которые имели запас задержки.
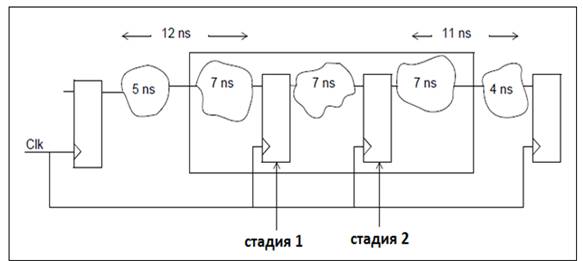
Рис. 3. Пример схемы после
конвейеризации
Процесс мультиплексирования представлен на рисунке
4.
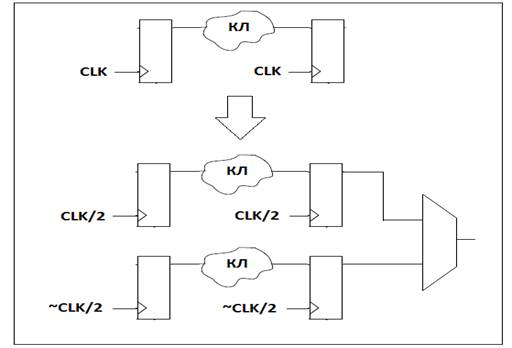
Рис. 4. Пример
мультиплексирования цифрового пути
При мультиплексировании КЛ не подвергается
изменениям. В данном случае один цифровой путь заменяется несколькими такими
же. При этом тактовая частота для каждого цифрового пути уменьшается и
вычисляется по формуле (3).
![]() , (3)
, (3)
где
Fnew - новая
тактовая частота,
Fold - исходная
тактовая частота,
m - требуемое
количество веток для распаралеливания.
Сравним данные методики повышения быстродействия с
точки зрения затрачиваемых ресурсов. Будем рассматривать простую синхронную
схему без обратных связей и работающую в одном тактовом домене.
Назовём условно количество дополнительных ступеней
конвейеризации глубиной конвейеризации, а количество веток мультиплексирования
– глубиной мультиплексирования.
Назовём, также, суммарное время Tc(смотрите
выражение (2)) всех цифровых путей в схеме, за вычетом суммарного времени всех
цепей КЛ, бюджетом времени( Tb).
![]() ,
(4)
,
(4)
где
Tb – бюджет времени СБИС,
Tl – время КЛ некоторого
цифрового пути.
Из (4) очевидно, что, если величина Tb ≥ 0 то требования
быстродействия СБИС удовлетворяются. В противном случае, будет существовать как
минимум один цифровой путь с задержкой на КЛ
превышающей максимально-возможную задержку цифрового пути для данной СБИС.
Дополнительное время для КЛ, при конвейеризации
приведено в выражениях (5) , (6).
![]() , (5)
, (5)
![]() , (6)
, (6)
где
Tpipe – дополнительное время для
КЛ,
Tff – суммарное время необходимое
для триггеров в цифровом пути,
Np – глубина конвейеризации.
Дополнительное время для КЛ, при
мультиплексировании приведено в выражении (7).
![]() , (7)
, (7)
где
Tmux – дополнительное время для
КЛ,
Nff – количество логических
путей в исходной схеме,
Nm – глубина
мультиплексирования.
Выражения (5) , (6) получены на основании того, что
при добавлении ступени конвейеризации выделяется дополнительный цифровой путь с
бюджетом времени Tc из (2). Выражение (7) получено из
условия, что при замене одного цифрового пути несколькими параллельными период
тактовой частоты повышается во столько же раз. При этом дополнительное время
вычисляется из разниц формул (2) для исходной
тактовой частоты и деленной тактовой частоты.
Из сравнения (6) и (7) следует, что процесс
мультиплексирования эффективнее процесса конвейеризации. И эта разница
определяется соотношением требуемой тактовой частоты и временными параметрами
триггера(т.е. выбором технологической линейки). По результатам
синтеза в Design Compiler
среднее время Tff составляет около 500пс. Для
тактовой частоты 1ГГц получаем, что мультиплексирование дает в два раз больше
дополнительного времени в бюджет при одинаковых глубинах конвейеризации и мультиплексирования.
Из рисунка 4 видно, что процесс мультиплексирования
ведет к значительному увеличению площади кристалла. Для оценки этого увеличения
будем использовать выражения (8) и (9)
![]() ,
(8)
,
(8)
![]() , (9)
, (9)
где
Sold – площадь схемы до
мультиплексирования,
Spipe – площадь схемы после
конвейеризации,
Sff – площадь триггера,
Smux – площадь схемы после
мультиплексирования,
Sdiv – площадь делителя
частоты,
Ssw – площадь дополнительного
мультиплексора.
Подставив, (6), (7) в (8),(9), используя (2)
получим выражения для Tmux, Tpipe
(10) (11).
![]() ,
(10)
,
(10)
![]() (11)
(11)
Далее положим, что количество триггеров в схеме
равно Nff и, что площадь последовательной логики
составляет 40% от общей площади [источник]. Пренебрегая величинами Sdiv и Ssw , получим:
![]() , (12)
, (12)
![]() (13)
(13)
где
S - величина равная разницы площадей до и после
оптимизации отнесенная к площади триггера.
Как видно из (12) и (13), Tpipe
в отличии от Tmux не зависит
от сложности схемы. Величина Tmux определяется
соотношением комбинаторной и последовательной логики. На рисунок 5 представлены эти зависимости. Из
рисунка видно, что при малой площади оптимизируемой схемы(S<50) более
эффективно мультиплексирование.
При содержании последовательной логики более 50%(ff) кривые перестают пересекаться и мультиплексирование
оказывается более выгодным по площади(рисунок 6).
На рисунок 7 представлен пример для более
быстродействующей библиотеки. В данном случае эффективность конвейеризации
возрастает т.к. относительная разница Tc и Tclk уменьшается.
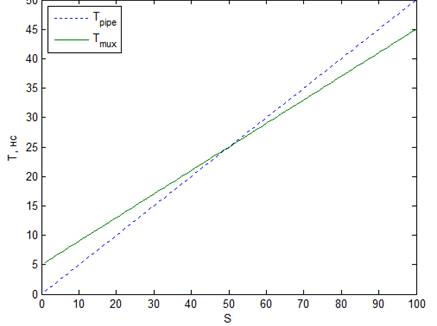
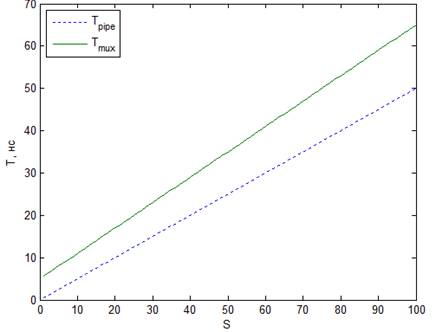
Рис. 5. Зависимости Tpipe
и Tmux от S. Tclk =
1нс, Tc =
0,5нс, Nff = 5, ff =
40% Рис. 6. Зависимости Tpipe и Tmux от S. Tclk = 1нс, Tc = 0,5нс, Nff = 5, ff = 60%
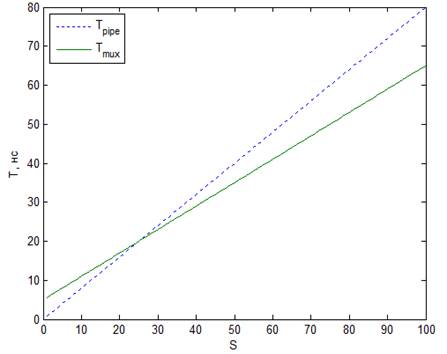
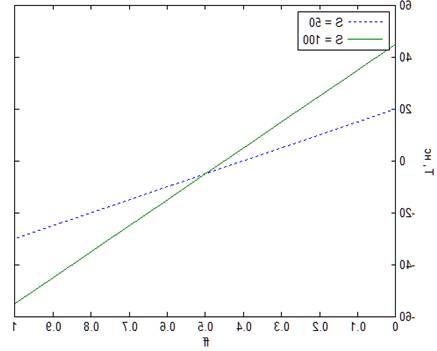
Рис. 7. Зависимости Tpipe
и Tmux от S. Tclk = 1нс, Tc = 0,8нс, Nff = 5, ff = 40%
Рис. 8. Зависимости разницы Tpipe и Tmux от ff для двух различных S.
Tclk =
1нс, Tc = 0,5нс, Nff
= 5
Из приведённых выражений и рисунков можно
заключить: для стандартных схем с долей содержания последовательной логики
меньше 40% более эффективным методом оптимизации оказывается конвейеризация;
для схем имеющих значительные технологические ограничения по быстродействию
и/или высокую долю последовательной логики(что зачастую оказывается связано) лучше прибегать к
мультиплексированию. На рисунке 8 приведена разница между Tpipe
и Tmux в зависимости от доли последовательной логики
для двух различных величин S.
Литература
1. Kwentus, Z. Jiang, and A. Willson, Jr., «Application
of filter sharpening to cascaded integrator-comb decimation filters» IEEE
Transactions on Signal Processing, vol.45, pp.457-467, February 1997.
2. J. F. Kaiser and R W. Hamming, «Sharpening the response of a symmetric nonrecursive filter» IEEE Transactions on Acoustics,
Speech, and Signal Processing, vol. ASSP-25, pp.415-422, October 1977.
3. S.J. Orfanidis, «Introduction to Signal
Processing». Upper Saddle River, NJ: Prentice Hall, 1996.
4. Y. Jang and S. Yang, “Non-recursive cascaded integrator-comb decimation
filters with integer multiple factors,” in Proc. 44th IEEE Midwest Symp. Circuits and Systems (MWSCAS), Dayton, OH.
5. Ричард Лайонс, «Цифровая обработка сигналов». Перевод с
английского. М: Бином – пресс. 2011.
6. Pramod K. Meher,
Javier Valls, Tso-Bing
Juang, K. Sridharan, and Koushik Maharatna, «50 Years of
CORDIC: Algorithms, Architectures, and Applications». Member, IEEE.
7. A Technical Tutorial on Digital Signal Synthesis. Analog Device. 1999.
8. Lakshmi Sri Jyothi Chimakurthy,
«DESIGN OF DIRECT DIGITAL FREQUENCY SYNTHESIZER FOR WIRELESS APPLICATIONS».
Auburn, Alabama August 8, 2005.