Идентификация дублирования и плагиата в исходном тексте
прикладных программ
В.В. Макаров,
доц./ст.н.с.,
к.т.н.,
доц./ст.н.с.,
Москва,
Институт проблем управления РАН
Плагиат можно встретить
практически в любой сфере общественной жизни: литература, искусство,
образование, журналистика, реклама, политика и т.д.
Плагиат – это умышленное
присвоение авторства на чужое произведение науки, литературы или искусства в
целом или в частности. По законодательству РФ нарушение авторских прав –
преступление. Потерпевший от плагиата автор может прибегнуть к гражданско-правовым
мерам защиты нарушенного права авторства, в том числе требовать возмещения
убытков. Помимо этого, нарушение авторских прав по российскому законодательству
также влечет и уголовную ответственность (ст. 146 УК РФ) даже в том случае,
если нарушитель прав автора не имел своей целью извлечение прибыли. Это
объясняется тем, что автору произведения данные действия могут нанести
значительный ущерб, как материальный, так и моральный.
Проблема плагиата в
образовании достойна отдельного внимания и заключается не только в незаконном
присвоении авторских произведений, но и в подрыве самой сути образовательного
процесса. Обучение – это двухсторонний процесс, в котором, с одной стороны,
учащийся усваивает знания, с другой стороны, преподаватель оценивает уровень
этих знаний. Но, скачивая из Интернета или «одалживая» реферат у товарища,
студент не усваивает ничего нового, не учится думать самостоятельно. И даже,
наоборот, привыкает пользоваться чужими мыслями, считая это нормой. А
преподаватель в свою очередь лишается возможности объективно оценить уровень
знаний своего подопечного – зачастую он даже не догадывается о том, что
проверяет плагиат.
Однако в последнее время в
Интернете становится все больше сервисов (таких как AntiPlagiat.ru, 2 БАЛЛА.ru
или PLAGIARISM.ORG), занимающихся поиском плагиата в студенческих рефератах и
курсовых работах. Большинство из них предоставляются бесплатно и не отнимут
много времени у преподавателя. К тому же поисковые машины Яndex и Google прекрасно
справляются с подобными задачами. Для поиска плагиата необходимо выбрать в
ученической работе произвольную фразу длиной 5-6 слов, заключить ее в кавычки
(поиск точного соответствия), и выполнить поиск [1].
Для обнаружения фактов
списывания студентами друг у друга, в настоящее время, так же разработано
некоторое количество программ (таких как WordCHECK, WCopyFind и
другие). Такие приложения позволяют сравнить две работы между собой, или работу
с внутренним архивом.
В технических ВУЗах многие
курсовые и лабораторные работы студентов состоят описательной и программной
части. Образовательный стандарт, а через него учебный процесс создают условия,
в которых одинаковые задания даются разным группам студентов в течение либо
одного семестра, либо в течение разных лет обучения. Студенты, плохо усваивающие
программу курса или, попросту, ленивые, как правило, «одалживают» у товарищей
из учебной группы или студентов старших курсов, выполненные лабораторные или
курсовые работы, и сдают их как свои выполненные самостоятельно, так как в сети
Интернет редко можно встретить ресурс, предоставляющий для скачивания программы
с исходными файлами и кодами. Поэтому и возникла необходимость разработки
работающей с внутренним архивом программной системы, позволяющей легко
изобличить списывание не только текста, но и программного кода, ведь средства
выявления плагиата в тексте не годятся для работы с кодами программ. Имена
процедур и переменных, комментарии, интерфейс программы и тому подобное могут
быть легко изменены злоумышленником, а коды разных программ, написанных на
одном и том же языке программирования, будут содержать большое количество
одинаковых строк.
Если списавший студент изменил
названия переменных, констант, процедур и тому подобное, будем считать, что
работа полностью списана, так как это не требует выдающихся знаний языка
программирования и является плагиатом. Но если студентами реализован одинаковый
метод решения поставленной задачи, это вовсе не означает, что работа является
плагиатом, ведь, прежде всего, оценивается знание предмета, а не оригинальность
решения.
Исходя
из сказанного, система выявления плагиата не может быть полностью
автоматической. Система должна замыкаться на преподавателя – лицо принимающее
решение (ЛПР). Описываемая система выявляет идентичные участки кода исходного
текста программ по группам языков программирования, т.е. исходные тексты
программ на Delphi, C++ и т.п., и показывает ЛПР эти участки для принятия решения о том можно
ли анализируемую работу считать плагиатом. Одним из важных параметров
анализируемого исходного кода является его авторство. Сам автор может
пользоваться своими прошлыми наработками. Это не является дублированием и тем
более плагиатом. Таким образом, если на входе системы имеется программа
ПРОГРАММАk автора АВТОРi, а в базе исходных текстов имеются другие программы
ПРОГРАММА1, …, ПРОГРАММАk-1 этого
автора АВТОРi, то анализ на плагиат
программы ПРОГРАММАk с
программами только этого автора производиться не должен.
Поиск плагиата в
программировании в данном случае основан на анализе характеристик кодов программ.
Любая программа имеет определенную иерархию структур, которые могут быть
выявлены, измерены и использованы в качестве таких характеристик. Применительно
к доказательству факта заимствования, эти характеристики должны слабо меняться
в случае модификации программы или включения фрагментов одной программы в
другую. Для этой цели лучше подойдет последовательность операторов программы,
поскольку модификация этой последовательности требует глубокого понимания
логики функционирования программы и является очень трудоемким процессом.
Реализация функции поиска
плагиата в программировании будет осуществляться для нескольких самых
распространенных языков программирования, к тому же предусмотрена возможность
добавления новых языков.
Сравнение программы студента с базой уже сданных работ
происходит следующим образом: вначале по базе операторов данного языка
программирования составляется последовательность операторов. Далее
анализируются частоты появления операторов программе. Частота определяется как
количество появлений конкретного оператора, деленное на количество появлений
всех операторов. Частоты отображаются в виде гистограммы. На абсциссе отложены
порядковые номера операторов, а на ординате - частоты появлений этих операторов
(рис.1). Идея такого способа идентификации плагиата опубликована в работе
С.Иванчегло [2]
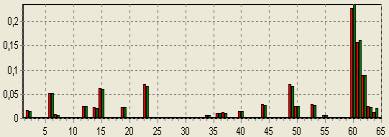
Рис.1. Частотный анализ
операторов программы.
При маскировке нелегально
заимствованного фрагмента злоумышленник может изменить некоторые операторы и добавить
новые, но в целом изменения, вероятно, будут малы, и ожидается, что
распределение частот останется практически тем же. Конечно, близкие значения
частот во фрагментах различных программ еще не являются доказательством факта
заимствования, но зато дают повод это подозревать.
Затем анализируется размещение
операторов в теле программы. Сравнение проводится следующим образом. Первый
оператор одной последовательности (программного кода из базы сданных работ)
сравнивается с последним оператором другой последовательности (проверяемого
кода). Если операторы одинаковы, то счетчик совпадений увеличивается на
единицу. Далее первая последовательность сдвигается и снова происходит
поэлементное сравнение.


Этот процесс продолжается до тех пор, пока не будет сравнен первый
оператор второй последовательности с последним оператором первой.
2
последовательность 1
последовательность ![]()


Для каждой итерации запоминается счетчик совпадений и длина
непрерывного участка совпавших операторов, другими словами длина списанного
фрагмента кода программы.
Полученная информация
изображается в виде гистограммы для каждого файла в базе сданных работ, на
абсциссе которой откладывается величина смещения одной последовательности
операторов относительно другой, а на ординате - количество совпадений
операторов при таком смещении (рис.2).
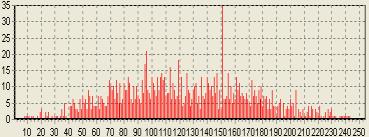
Рис.2 Частотный анализ
фрагмента копирования по исходному тексту базовой работы.
Пик, наблюдаемый на рисунке,
возник из-за того, что в этих программах встречаются одинаковые фрагменты. Для
«основных» пиков на графике выводится на экран код проверяемой программы и уже
сданной работы из базы с выделенными фрагментами, соответствующими пику.
Признать такое заимствование плагиатом или нет, решает преподаватель,
основываясь на величине фрагмента, его роли в программе, схожести стиля
программирования.
Рассмотренный подход позволил
точно выявить участки дублирования в исходных текстах модулей и факты плагиата
с использованием базы исходных текстов на Delphi, С++, MS Visual Basic и
Java, содержащей к настоящему времени около 60 файлов.
Литература
1.
Colin J. Neill, Ganesh Shanmuganthan. A Web-Enabled Plagiarism Detection
Tool. IEEE IT Pro, September/October 2004. перевод: Колин Нейл, Ганеш Шанмагантан. Web-инструмент для выявления плагиата. Открытые системы №
1, 2005, с.40-44.
2.
С. Иванчегло. Методы
выявления плагиата в программировании .Software, №49, 2000. http://www.kv.by/index2000491105.htm