Использование метода
«тезауруса» при проектировании систем
с
недетерминированными алгоритмами
А.И.
Разумовский,
мнс,
ИПУ РАН, г. Москва
Главным средством
описания и инструментом взаимодействия человека с фактами и явлениями окружающей
среды является естественный язык. В формулировке Ф.Гегеля эта сентенция
выражена следующим образом: «Формы мысли выявляются и отлагаются прежде всего в
человеческом языке» [1]. Таким образом, в применении человеческого языка можно
прослеживать не только поверхностные семантические связи, но и второй слой
намеков и комментариев, а также возможности описания альтернатив или
неточностей. Посредством естественного языка формируются практически любые
описания, а также успешно контролируются сложность или расширения задачи. Для
этих целей вводится понятие тезауруса – множества замкнутых смысловых
лингвистических конструкций (фраз и предложений) предназначенных для описания
на естественном языке идеом (целей, условий и пр.) алгоритма.
При создании автоматизированных
систем достаточно часто оказывается, что на этапе разработки технического
задания не удается полностью учесть отдельные операции алгоритма
функционирования систем из-за сложности понимания некоторых процессов в
системах, а также из-за постоянных изменений технических заданий на систему со
стороны заказчика, что встречается чаще. В частности, это касается алгоритмов
обработки сложно структурированных
геометрических объектов. Как правило, случается так, что если по разработанным
алгоритмам уже написана программа, то порой внести изменения в программу
становится равносильно написанию ее заново и связано с большими дополнительными
затратами.
Главное внимание
сосредоточено на проблеме использования тезаурусов в системах с
недетерминированными алгоритмами на примере обработки геометрических объектов.
Недетерминированный алгоритм рассматривается, как слепок факта человеческого
мышления, и, следовательно, процесс его реализации неким оптимальным образом
должен содержать формы и атрибуты мыслей, а также включать механизм логического
перехода от данной мысли к последующей.
Особенно, при
определении и формировании тезаурусов следует обратить внимание на биполярность
качественного и количественного подхода в процессе именования элементов, что
непосредственно соответствует основополагающему факту истолкования феноменов
системы. Тем самым наблюдается и реализуется тенденция унификации свойств
отдельных модулей, алгоритмов и прототипов, которая выражается в стремлении
снизить влияние на разработку программных систем количественного фактора за
счет поиска и сведения обобщенных естественно-языковых определений в
унифицированные группы.
1. Характеристики
недетерминированных систем
Если задача может
быть решена прямым способом, говорят, что она имеет детерминированный метод
решения. Детерминированные алгоритмы всегда обеспечивают регулярные решения. В
них отсутствуют элементы, вносящие неопределенность, кроме того, для них
невозможна произвольность в выборе решений, определяющих последовательность
действий. Для построения детерминированных алгоритмов недопустимо применение
методов проб и ошибок. К задачам, имеющим детерминированные решения, относятся
математические уравнения, а также такие задачи, как проверка данных и печать
отчетов.
Если решение задачи
не может быть получено прямым методом, а выбирается из заранее определенного
множества вариантов, такая задача имеет недетерминированное решение. Алгоритм
недетерминирован [2] если для его реализации используются методы проб и ошибок,
повторов или случайного выбора. К классу недетерминированных алгоритмов можно
также отнести алгоритмы, которые предназначены не для поиска ответа на
поставленную задачу, а для моделирования физических систем.
В [2] определяется,
что недетерминированный алгоритм
описывает систематическую процедуру поиска нужного решения среди, всех
возможных. Его существование в первую очередь зависит от построения множества
потенциальных решений, в котором содержится искомое. Такое множество может быть
предварительно описано в форме естественно-языковых директив, называемых
тезаурусом, содержащих сущностную канву проблемы. Исходные посылки для
выявления содержания тезауруса таковы:
1. Выбирается
первичный термин ключа, и ставятся к нему специальные вопросы: что, как, когда,
сколько, какой.
2. Составляются содержательные
фразы, соответствующие отношению к выбранному термину. Такие фразы могут
содержать выбранный термин в дательном либо винительном падежах.
3. На основе
выбранного термина, а также результатов 1 и 2 пунктов делается попытка
образовать комплексные составные предложения, фокусирующие внимание на
обстоятельства сопровождения – обстоятельства времени, места, причины и цели.
4. Составляются
сложно подчиненные предложения или словосочетания из фраз, определенных в
результате предыдущих пунктов с использованием союзов: посредством, через,
сквозь, потому что, для. Такие предложения должны обозначать внутренние
взаимодействия в системе, а также стимулировать развитие тезауруса.
5. Попытаться
провести сортировку найденных фраз и предложений по порядку смыслов: 1)
«Известно - Нет», 2) «Возможно - Нет», 3) «Разделимо - Нет», 4) «Достаточно -
Нет».
Построение тезауруса
должно приводить к созданию предметной абстракции. Такая абстракция может
включать в себя: 1) типизация термина-ключа – фиксированные элементы поиска и
хранения результатов определенным образом в определенном классе; 2) реализация
прототипов функций, именованных действительным глаголом типа – искать,
сравнить, считать, а также прототипов данных.
При проектировании
систем с недетерминированными алгоритмами очень важно формулировать
естественно-языковые описания, при обязательной фиксации получающихся
абстракций в объектно-ориентированной или иной форме. И, наоборот, для задания
ограничения контекста тезауруса конкретной задачи служат абстрактно определенные
среды: среда условий, среда процесса, среда результатов. Каждая из сред должна
быть адекватна другой прежде всего терминологически (например: термин
«координата» имеет равное значение и в среде условий, и в среде результатов), и
затем логически - через использование единой системы отсчета, а также
посредством единого способа представления (формата) данных.
2. Тезаурус и анализ
предметной области задачи
Идея составления
тезауруса для задачи построения алгоритма программной системы (ПС) формирует дополнительные
вопросы о возможном контроле над имеющимися в арсенале разработчиков именами –
терминами. Резонно предположить, что среди множества присутствующих в проекте
ПрИС функциональных и информационных элементов существует общность
«поведенческих» свойств, выявляя которые возможно уменьшить количество
управляющих процедур и, следовательно, повысить общий контроль над структурой
системы.
Существует, также и
еще одна проблема, касающаяся требований доработки (или изменения) программного
кода, который либо реализован вручную, т.е. без специальных CASE- средств,
либо, – кода, состоящего из разнородных включений на нескольких языках.
Составление тезауруса
недетерминированного алгоритма задачи обусловливает анализ системы и определяет
уровень ее качества. Так для САПР основными характеристиками, наряду с
программными определениями, как алгоритм, процедура, данные, в тезаурусе задачи
должны быть учтены термины: графический объект, точка, тип линии и так далее. В
соответствии с уровнем детализации задачи тезаурус разделяется на слои, каждый
из которых имеет собственную предметную базу. Тем самым изначально
гарантируется изоляция друг от друга несовместимых понятий, и, следовательно,
им соответствующих элементов структур.
Итак, можно
представить исходную задачу, как множество однородных и разнородных
элементов-терминов, таких как, например, взаимодействие - и тип данных, поток
информации - и поток тестирования, пересечение – и точка пересечения. Если
предположить существование простого линейного описания процесса разработки
алгоритма, тогда следует определить этапы
такого процесса. То есть, необходимо выделить в сложном русле разработки
ПС некие реперные точки, которые могли бы служить для образования контрольных
участков исследования поведения такой системы, что формирует локальные алгоритмы. Сравнивая существующие
на сегодняшний день технологии моделирования процесса разработки программных
систем посредством стандартов IDEF[3] или описания
модели системы средствами языков моделирования типа UML
[4], можно выделить качественные основные различия между ними и рассматриваемым
здесь методом тезауруса.
UML – применяют, когда процесс
моделирования основан на рассмотрении прецедентов использования, является
итеративным и пошаговым, а сама система имеет четко выраженную архитектуру. Он
не может быть использован для определения порядка, качества и сущности моделей,
создаваемых в конкретных задачах [4].
IDEF основан на концепции графического
представления блочного моделирования. Графика блоков и дуг IDEF-диаграммы отображает функцию в виде
блока, а взаимодействие блоков друг с другом описываются посредством
интерфейсных дуг, отображающих порядок выполнения и управления функций [3].
Отсутствие в технологиях IDEF и UML возможностей учета именованных
элементов вне зависимости от стандартного изображения предлагаемых IDEF и UML схем ведет к невозможности полного и
более тщательного в нюансах описания требований и решений системы, тем более, в
задачах недетерминированного свойства, т.е., в случае поиска «пробных» и гибко
изменяемых решений. Различия между использованием метода тезауруса и методов на
основе модельных описаний посредством IDEF или UML лежат в плоскости возможности или
невозможности описания задачи на естественном языке. В случае выбора метода тезауруса, представляется
возможным осуществить полное подробное описание задачи или отдельных ее свойств
и, затем, последовательно сгенерировать конкретную для данной задачи
абстракцию. В случае выбора способа моделирования средствами специализированных
языков IDEF
или UML - модель
системы придется создавать при помощи схем и элементов стандартной квалификации
и формализации, что проще в случае простой системы или системы с очевидным
ожидаемым поведением и весьма непросто (невозможно) – при решении
недетерминированных задач.
Таким образом, перцепция идеи
составления тезауруса для задачи проектирования модуля программной системы
формирует дополнительные вопросы о возможностях контроля над имеющимися
именованными ее элементами. Поэтому, резонно предположить, что среди множества присутствующих
в проекте модуля функциональных и информационных элементов есть общность
поведений, находя и выделяя которые достижимо такое состояние проекта, в
котором снижено число управляющих процедур и, следовательно, растет общий
уровень контроля над качеством оптимальной структуры системы.
3. Содержание метода
Тезаурус должен
состоять из фраз и предложений, основанных:
1) на основных
терминологических ключах;
2) на актуальных
приоритетах таких ключей;
3) контекстной связи
между иными прочими элементами.
Актуальность
сортировки элементов тезауруса означает актуальность последовательности
действий над ними, т.е. их определения (уточнения) и кодирования.
Качество представления информации,
качество ее содержания, а также качество связей между элементами данных ключевым
образом сосредоточено в некоей возможности единообразия записи информации,
причем в разной форме и различного наполнения, реализуя, следовательно,
возможность сосуществования множества тезаурусов. Поэтому наряду с вопросами
создания тезаурусов системы, необходимо исследовать также возможность
минимизации типов данных для хорошей управляемости элементами информации в виде
источников хранения и передачи на терминалы.
Существуют
концептуальные трудности при проектировании алгоритмов посредством метода тезауруса.
Эти трудности связаны, прежде всего, с выбором правильных терминов-ключей и
фраз для наполнения тезауруса, т.е. – выбором способа решения задачи, который
соответствовал бы ее условиям (верный стиль, масштаб, способы кодирования
данных, точность представления информации и т.д.). Это свидетельствует о
необходимости выработке четких правил для именования и сортировки элементов.
Элемент тезауруса можно изобразить в
виде вершины, в общем случае, ненаправленного графа. Дуга обозначает
возможность дальнейшей детализации
первичного термина либо фактор причинно-следственного, абстрагирующего,
ассоциативного, комментирующего перехода к иной вершине графа, соответствующей
определенному элементу тезауруса. В частном случае – образуется
терминологическая сеть.
Смысловые содержания понятия «дуга»
относится к процессу конкретизации описания элемента системы, либо, наоборот, –
к обозначению возможностей создания абстрактной сущности. Понятие «дуга» может
быть также соотнесено с наличием (возникновением) ассоциативных связей между
элементами. «Дуга» может также отображать выделение отдельного элемента в плане
повышения его значимости или вынесения элемента за пределы проекта. Таким
образом, корневые элементы, т.е. элементы, имеющие лишь входящие дуги, должны
определить основные детали алгоритма.
В настоящее время используются две
стратегии создания алгоритма посредством метода тезауруса. Первая стратегия
основывается на формировании предложений и фраз повелительного наклонения, с
обозначением действий прежде всего через глаголы – найти, сравнить, сохранить:
1) Жесткое именование требуемых
процедур (формулировка). Основной шаблон фразы: Найти I-элемент, находящийся в определенном
элементе –J.
Результат: последовательность формулировок
поиска всех декларированных элементов, в виде прототипов функций.
2) Сортировка прототипов функций по
параметрам – передаваемым в функцию извне и хранимым в едином пространстве
результатов.
Результат: совмещение процедур по
типам входящих и исходящих данных. Функция, осуществляющая поиск символьного
элемента в строке, будет иметь результат, записанный в символьном виде для
фиксации результата поиска, а также – для постановки обновленных условий
дополнительных операций. Это позволит регулировать последовательность
выполнения локальных алгоритмов комплекса, в плане одновременного
первоначального учета всех необходимых условий, либо – через добавление новых
условий в процессе создания сложного алгоритма.
Вторая стратегия имеет диалоговый
характер, основываясь на фразах- парах, первая из которых имеет специально
вопросительную форму (какой, что, сколько), а вторая – утвердительную форму,
соответствующую ответу на поставленный вопрос.
1а. Какой <параметр> из <>
соответствует <параметру> из <>?
1б. Параметр N находится внутри M, и может быть выражен через систему
координат M.
2а. Сколько возможно получить
результирующих данных?
2б. Количество результатов может быть
бесконечно.
Результатом данной стратегии является
создание прототипов операций и типизированных информационных хранилищ данных.
Естественно, что, в плане комплексных
алгоритмов, допустимо многократное ветвление формулировок, каждая из которых
стремится уточнить предыдущую, относящуюся к одному смысловому (контекстному)
полю. Это ветвление трактуется, как встроенная операция, локальный алгоритм.
4. Построение
алгоритма пересечения контура линией
При разработке алгоритма поиска
множества точек пересечения произвольного замкнутого контура, состоящего из N
вершин, и прямой линии сперва обнаруживается видимая простота решения.
Действительно, имея параметрически заданную прямую, представляется несложным
последовательное пересечение данной линии и прямых отрезков контура (рис. 1).
Представляя настоящую задачу, как
задачу, отображающую реальное требование, когда нахождение множества
качественных элементов существует в контексте более общей задачи, задачи
штриховки, построения эквидистантных контуров и пр., - оказывается очевидным,
что описание требований общей задачи превосходит частные предписания внутренней
задачи, как, например, здесь: нахождение множества точек пересечения линии и
контура.
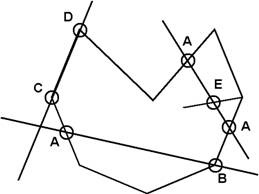
Рис. 1
Обычное алгоритмическое решение,
называемое методом четных и нечетных точек, таково. Каждая нечетная точка
пересечения (1-ая, 3-яя, и т. д.), - в ряду точек, упорядоченных по координате
в D1-системе координат, связанной с секущей линией, - будет началом отрезка
штриховки, а четная - концом. В простых случаях, показанных на рисунке 1
точками А и В проблемы не возникает - множество точек пересечения
состоит из неповторяющихся точек.
Иной случай изображает точки C, D и E. Здесь обнаруживается либо три точки
пересечения (А, E,
А) и, следовательно,
по методу четных и нечетных точек, - только один результирующий отрезок, либо параллельность
линии и одного из отрезков контура (C, D), что требует дополнительных исследований – пересекает ли
линия контур или происходит только касание его. Таким образом, проявляется
дилемма: либо для разрешения данной задачи, в том числе - конкретного случая (А,
E,
А) формулировать и
решать дополнительную подзадачу, исходные данные которой будут базироваться на
найденном уже множестве точек и вспомогательных условиях, определяемых
дополнительно. Либо рассматривать дополнительные условия в совокупности с
известными прежде, усложняя постановку задачи, и планировать новое её решение.
Однако, в первом случае, производится
обработка «пропущенной ситуации». При этом не существует гарантий того, что
матрица состояний исчерпана. Иначе говоря, не исключается возможность
проявления новой «пропущенной ситуации», для которой потребуется новый
поиск решения. Второй вариант действия кажется более универсальным и
застрахованным от возникновения непредвиденных проблем. В действительности же,
этот вариант действия качественно не отличается от предыдущего.
Производя максимальное наполнение
тезауруса в виде фраз, соотносимых со смысловыми описаниями точек пересечения,
оказывается очевидным возможность избавиться от появления «пропущенных
ситуаций» через формирование диалогового тезауруса задачи (таб.1).
Таб. 1.
Диалоговый
тезаурус алгоритма пересечения
|
1) Какой параметр контура содержит факт взаимодействия с
линией; |
|
|
1а) номер сегмента контура; |
Цикл
последовательно по сегментам контура. Тип Point должен включать факт взаимодействия
линии и контура. |
|
2) Какой параметр контура содержит качество его взаимодействия
с линией; |
|
|
2а) Факт совпадения с одной или двумя вершинами, а также -
наличие равных по значению параметров пересечения; |
Создание
по факту сорта точки пересечения |
|
3) Какое количество результирующих данных можно получить; |
|
|
3а) Бесконечное число точек пересечения. |
Создание
хранилища точек пересечения в виде шаблонного класса вектор - vector<Point> |
В результате, имеем несколько
локальных алгоритмов:
- функция, имеющая параметром
входа-выхода массив данных типовых точек, а также содержащая последовательный
проход по всем отрезкам контура для определения частного взаимодействия каждого
из сегментов с исходной линией, организованный в виде цикла;
- тип точки Point организуется включением в его описание
факта координаты места взаимодействия - номер сегмента пересечения, координата
в глобальной D2
системе координат, а также сорт (качество) точки взаимодействия. В ‘С’ нотации
модно записать:
struct Point {
int index; // номер сегмента контура,
к которому относится эта точка
double par; // координата точки в системе
D1
SortPointInters sort;
// «качество» точки пересечения
IntersPar():index(0),par(0),sort(GRAZE),pl(0){}}.
Сорт (качество) точек пересечения
(точек взаимодействия) определяет разделение всех точек пересечения по
терминологическим группам в нотации языка ‘C++’:
enum SortPointInters
{ GRAZE , // касательная к сегменту контура
MATCH ,
// координатное совпадение точки пересечения с другой
PASS,
// нормальное пересечение
MATCH_PASS, ,
// при пересечении - совпадение с
другой точкой
GRAZE_PASS, ,
// при пересечении - касание к
первой и (или) второй точке сегмента
GRAZE_MATCH, //
касание и одновременное совпадение с другой точкой
GRAZE_MATCH_PASS}; //
пересечение происходит через другую точку и совпадает с одним или с
двумя концами сегмента контура.
- Массив результатов, который можно
организовать с применением шаблона vector: vector<Point>.
Таким образом, на основе создания
диалогового тезауруса путем задания трех основных вопросов: о факте содержания
взаимодействия линии и контура, о факте качества точек пересечения, а также о количественном
факторе наличествования всех возможных точек пересечения, удалось реализовать
основную канву алгоритма пересечения контура прямой линией в виде совокупности
формальных локальных алгоритмов. Это означает, - очевидную возможность контроля
изменяющейся структуры программной системы, а также устойчивость ее
функционирования.
Выводы
1. Осуществление создание программной системы
недетерминированного поведения методом тезауруса позволяет произвести поиск и
формулировку задачи до времени ее реализации – абстрагирования, формализации.
Во многих случаях возможна формулировка с применением терминов «пространство
условий», «пространство поиска», «пространство результатов», «координаты
результатов».
2. Для проведения формализации системы
(алгоритма системы) необходимо подготовить «смысловую» основу, в виде
естественно-языковых предложений и фраз – и это цель и задача метода тезауруса.
3. Исходя из набора неформальных
формулировок в виде специально подобранных и последовательно подготовленных
предложений и фраз, оказывается возможным выделить сущностные элементы,
посредством упорядочивания (смысловое, морфологическое, ассоциативное, целевое,
диалоговое) которых, создать далее структуру алгоритма задачи в виде
повелительного или диалогового тезауруса.
Общая схема проектирования
естественно-языкового базиса недетерминированного алгоритма методом тезауруса
такова:
1) Установление основных понятий
задачи, включая термины контекста задачи и ее целей. Во всех вариантах задач
используются основные алгоритмообразующие наименования: «Искать - что»,
«Сравнить -что».
2) Формирование фраз на основе
выбранных терминов и вопросительных слов - что, где, как: «Искать – что? -
подстроку», «Сохранить – где? – в сортированном массиве».
3) Формирование фраз, содержащих
наименования формата хранения результатов, способа их соответствия исходным
данным, а также формы доступа, в системах жесткой временной или
многопользовательской синхронизации.
4) Формирование фраз, содержащих
информацию об изменении исходных параметров. Например, в случае изменяемого в
процессе решения количества вершин полигона.
5) Формирование фраз, характеризующих
последовательность выполнения имеющихся операций.
6) Поиск фраз,
связанных с возможными неявными условиями процесса разработки алгоритма.
Исследуется влияние человеческого фактора, а также его влияние на качество
конечного алгоритма.
Условия 4, 5 и 6 могут быть не
востребованы для простых задач.
Литература
1. Гегель Г. Наука логики. Ч. 1. М.,
1970.
2. Зиглер К. Методы проектирования
программных систем. М. Мир,
1985.
3. Godwin A.N., Gleeson J.W., Gwillian D. An assessment of the IDEF
notations as descriptive tools. – Information systems, V14, N1, P13-28, 1989.
4. Буч Г., Рамбо Д., Джекобсон А. Язык
UML. Руководство
пользователя. М., ДМК,
2000.